Just about every modern office job involves users interacting with a computer for the bulk of their work day. So excessive waiting for the computer to respond to actions can lead to both user frustration and decreased productivity.
In short, users like speed!

A study published by Nielsen Norman Group at the dawn of the internet era established some rule-of-thumb response time standards that still hold true today:
- 0.1 second is about the limit for having the user feel that the system is reacting instantaneously.
- 1.0 second is about the limit for the user’s flow of thought to stay uninterrupted, even though the user will notice the delay.
- 10 seconds is about the limit for keeping the user’s attention focused on the dialogue. For longer delays, users will want to perform other tasks while waiting for the computer to finish.
In our experience with Valence apps, any response time exceeding a couple seconds is going to feel excessively sluggish to most users. A sub-second response time is a good standard to shoot for, and for most Valence apps this should not be a problem. Thanks to intelligent browser caching and Apache Server compression settings, the time behind the initial load of a Valence app is generally quite fast. Typically it’s the server-side database access time via SQL that offers the biggest opportunity for in-app performance improvements, and that is the focus of this post.
Most Valence apps harness the power of SQL on the back-end to leverage the “best of both worlds” — easy coding and fast performance. Developers simply build up an SQL select statement, pass it into VVOUT (or run it through Nitro App Builder / NAB), and the SQL engine on IBM i automatically picks the best index or logical file to rapidly build out the result set in JSON format for viewing in the browser.
The “Active Sessions” app in the Valence Portal is a good benchmark for the kind of performance most grid-based apps should strive for when pulling data from IBM i. As you can see in the back-end RPG source (the “LoggedInList” procedure inside source member VVWLI in QRPGLESRC), this program employs a very straightforward SQL-based page load. If you launch the app and open your browser’s developer tools to inspect the network response, you’ll see that each click of the refresh button in the app should result in grid page reloads of well under a second.
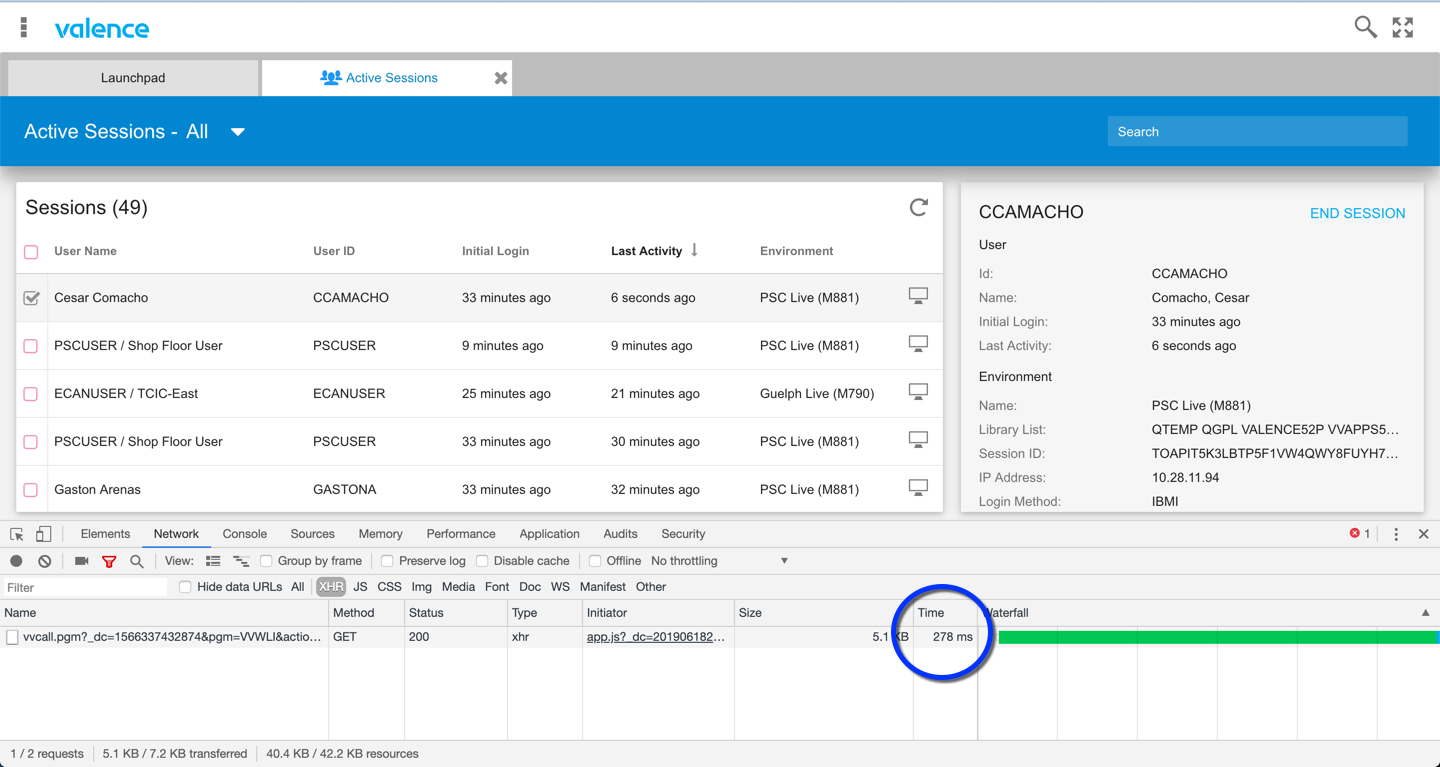
The SQL engine handling the IBM i DB2 database generally does a great job finding the best access paths (i.e., logical files or indexes) to quickly access the requested data in a SELECT statement built over physical files or tables, even building reusable temporary indexes (aka Maintained Temporary Indexes, or MTIs) when necessary. However it’s not ideal to rely on MTIs for frequently used queries, as the system may decide to dispose of these indexes at any time — particularly when they are very large — and thus be forced to recreate them, which can of course slow down response time considerably. So it’s ideal to have in place, where practical, the right indexes necessary to match your WHERE or ORDER BY specifications so the SQL engine can make use of them.
The point of this article is not to restate what’s already been stated elegantly and in great detail about indexes elsewhere. There are plenty of resources available on-line explaining how to access and use the Index Advisor via the IBM Navigator for i (formerly known as the System i Navigator), such as the IBM Knowledge Center and this IT Jungle Article from a few years back. You can also find some great information from IBM on index performance strategies.
However there is one nuance to indexes you should be aware of when using either Valence’s VVOUT SQL tools or NAB and its default settings, and that refers to the SQL sort sequence. By default Valence uses an SQL sort sequence (SRTSEQ) of *LANGIDSHR, which gives equal weight to character fields regardless of case. So “aaa” and “AAA” are treated as the same value when it comes to WHERE and ORDER BY clauses.
This brings us to a key point with regard to speed: When this *LANGIDSHR sort sequence setting is being used on SQL statements, indexes containing one or more character fields in the key that are using the standard *HEX-based sort sequence may not be considered eligible by the SQL optimizer when running SQL statements through VVOUT or NAB. This can cause a noticeably slower response time when ordering and/or filtering data over larger files where an MTI must be built. Again, this is specific to character fields — if your SQL selection or sort criteria involve strictly numeric fields, date fields, etc. then this sort sequence setting should have no impact.
So if you suspect you have an SQL statement taking an inordinately long time to run, especially when compared to running the same statement in STRSQL or Access Client Solutions (ACS) where the default SRTSEQ is *HEX, then the sort sequence setting may be the reason. You can confirm this is the case by temporarily switching the sort sequence to *HEX in Valence and then retrying the query to see if it runs faster. You can override the SRTSEQ value in three ways:
- In Portal Admin > Settings > Hidden Settings (which appear only if you have hidden settings turned on in Portal Admin > Settings > Portal Administration > “Show hidden settings”), switch the “Default SQL sort sequence (SRTSEQ)” setting from *LANGIDSHR to *HEX. This will apply universally to RPG programs using vvOut and NAB data sources, except where overridden, as specified in (2) and (3) below.
- For an RPG program calling vvOut_execSQLtoJSON, set field VVOUT.SRTSEQ to ‘*HEX’
- For a NAB data source, open up the “Advanced” section on the save window and set the sort sequence to *HEX.
While changing the sort sequence to *HEX may speed up the performance, the resulting case-sensitive nature of filtering and sorting may be less desirable for your users. So the ideal solution would be to create a *LANGIDSHR-based index. How you do this depends on which medium you’re using:
- When creating a new index from the IBM Navigator for i index advisor, be sure to click on the “Options” tab and specify a Sort sequence table of “Shared-weight table” before hitting OK on the index creation.
- When creating a new index from within STRSQL, hit F13 to go into services, select option 1 (“Change session attributes”), page down and change the Sort sequence value to *LANGIDSHR. Then go back and issue your CREATE INDEX command.
- When creating a new index from within ACS, go to Connection > Edit JDBC Connection, select the Language tab, then change the Sort sequence table to Shared-weight table. Then run your CREATE INDEX command in the execution window.
Note that to override the sort sequence setting in Valence you must be on build 5.2.20190528 or later. Prior to that release the universal default was *LANGIDSHR with no mechanism for overriding to *HEX. However for most locations the shared-weight sort and select will be more appealing to users, so we recommend you focus on adding or changing your character-based indexes instead.
Happy speeding!